In the previous post we talked about the performance improvement we obtained for the Canny edge detection algorithm. Most of the changes we did there were focused on hot loops: making memory accesses sequential and making the loops longer, which in turn allowed the compiler to autovectorize them. This made our program run significantly faster because we used the hardware resources we had at our disposal more efficiently.
Most modern processors, including embedded processors, will have more than one CPU core. Our next performance improvement idea would be to take advantage of the additional CPU cores.
In this post we use OpenMP to achieve parallelization. OpenMP is a standard that allows porting single-threaded code bases to multicore systems using compiler pragmas and special library calls. The good thing about OpenMP is that all the major compilers support it and that it is simple to port the existing single-threaded code to a multi-threaded environment. If the compiler does not support OpenMP, it ignores the pragmas but nevertheless you are still left with well-built, single-threaded code.
As a starting point we are using an optimized single-threaded Canny source code which we created in the previous post 1. Ideally you want to start with a serial source code that is well optimized for a single processor; using an unoptimized code base will also yield performance improvements, but it might happen that the well-optimized single-threaded version is as fast as an unoptimized multithreaded version. And multithreading comes with downsides: increased energy consumption and overhead that becomes significant if the input size is small.
Profiling
As most of the time when doing performance analysis, we start off with profiling. We want to see which functions have the longest runtime and focus our work there. Here is the flamegraph of the Canny algorithm for a really large image (15360 x 8640 pixels).
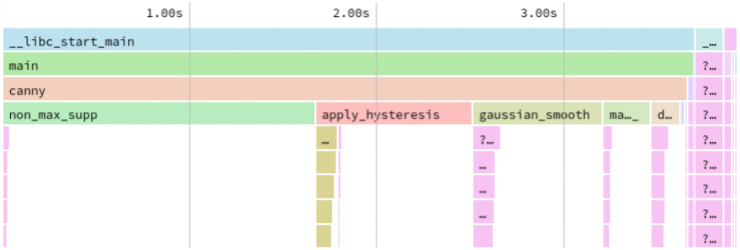
Functions that dominate the profile are non_max_supp, gaussian_smoth, apply_hysteresis. Functions derivative_x_y and magnitude_x_y take only a few percent of the runtime, but if we manage to speed up other functions, they can also appear significantly in the profile.
A note: in the following tests we are measuring only the runtime of the Canny algorithm. The main part of the program is the algorithm itself, but there are a few other functions, like reading and writing the image, parsing arguments that take time; we are not measuring the non-algorithmic parts.
Analysis
Function non_max_supp
The function that takes the largest amount of time is non_max_supp. If we look at the source code., we see that it processes the image pixel by pixel, going through the image row-wise. This is a good pattern as it uses available memory bandwidth optimally. The function contains a loop that consists of many nested if conditions These are difficult to parallelize using SIMD 2; however, splitting the workload between several CPU cores is perfectly suitable for parallelizing complex control flows.
The only thing we need to make sure is that the iterations of the outer loop are completely independent of one another 3. This was simple to check because each iteration was writing to a different value of the output array resultptr, which is the only output array in the program.
Originally, the loop header looked like this:
for (rowcount = 1, magrowptr = mag + ncols + 1,
gxrowptr = gradx + ncols + 1, gyrowptr = grady + ncols + 1,
resultrowptr = result + ncols + 1;
rowcount < nrows - 2; rowcount++, magrowptr += ncols,
gyrowptr += ncols, gxrowptr += ncols, resultrowptr += ncols) {
for (colcount = 1, magptr = magrowptr, gxptr = gxrowptr,
gyptr = gyrowptr, resultptr = resultrowptr;
colcount < ncols - 2;
colcount++, magptr++, gxptr++, gyptr++, resultptr++) {
m00 = *magptr;
...
if (...) {
if (...){
if (...) {
...
} else {
...
}
} else {
...
}
} else {
...
}
*resultptr = ...
}This is a very complicated loop header and it is not possible to parallelize using OpenMP since OpenMP requires loops to satisfy the canonical loop form. The essence of the canonical loop form is that the loop trip count can be predicted before the loop starts (more details in section 2.6 of the OpenMP specification). To achieve this, the loops need to:
- Be a for loop (while and do-while loops are not supported).
- Use one loop index variable to iterate the loop.
- The initialization of the loop is a simple statement assigning a start value to the loop index variable (e.g.
i = 0ori = m). - The loop condition is a simple arithmetic condition. No variables in the loop condition change their value in the loop except for the loop index value (e.g.
i < NandNdoesn’t change the value inside the loop). - The loop increment is known at compile time (
i++ori+=2).
The code inside the loop body dereferences induction pointers to access data (*magptr, *gxptr, *resultptr, lines 10 and 26). What we want to do instead is to access data with array-based notation (magptr[index], gradx[index], etc). This transformation will allow us to verify easily that the iterations are independent and it will also make it easier for the compiler to optimize our code.

Subscribe to our newsletter
and receive in-depth technical articles, white papers, videos, webinars, product announcements, and more.
In our case, it was possible to transform the two loops to OpenMP canonical form. Here is what the header looks like:
for (rowcount = 1; rowcount < nrows - 2; rowcount++) {
int row = ncols * rowcount;
for (colcount = 1; colcount < ncols - 2; colcount++) {
int index = row + colcount;
m00 = mag[index];
if(...) {
….
}
else {
…
}
…
result[index] = ...
}
}
Both loops are now simple loops that comply with the OpenMP canonical form. We introduced two new variables row and index to calculate the offset in the input and output arrays. For example, instead of accessing array mag using *magptr, where magptr is an induction pointer variable whose access pattern is not easily understood, we are accessing using mag[index] (line 5).
To distribute the loop to multiple CPU cores, we use OpenMP pragmas. Here is the source code of the previous loops with OpenMP pragma. Note that no modification is done to the source code of the loop, the only thing we did is to introduce the #pragma.
#pragma omp parallel for shared(result, mag, gradx, grady, ncols, nrows) private(rowcount, colcount) default(none)
for (rowcount = 1; rowcount < nrows - 2; rowcount++) {
int row = ncols * rowcount;
for (colcount = 1; colcount < ncols - 2; colcount++) {
int index = row + colcount;
m00 = mag[index];
if(...) {
….
}
else {
…
}
…
result[index] = ...
}
}
Note the #pragma … on line 1. This pragma will tell the compiler to create a version of the loop that can be distributed to multiple CPU cores. Here is the meaning of the keywords in the pragma:
omp– marks the pragma as OpenMP pragma.parallel– creates a parallel region. Inside the region, the same code will be executed by several threads.for– distributes the for loop among several threads that will run concurrently on different CPU cores. It also splits the iteration space according to the number of threads and assigns each part of the space to a thread.shared(...)– variables listed inside the parenthesis are shared among the threads. All read-only variables (mag,gradx,grady,ncols,nrows) should be shared to prevent unnecessary copying. Output arrayresultis also shared because each thread writes to a different part of the array.private(...)– variables inside the parentheses are private to each thread, i.e. each thread has its own copy. The loop index variable should be private because each thread will get a range of values for the loop index variable to work on (e.g. thread 0 will getrowcountfrom 0 to 199, thread 1 will getrowcountfrom 200 to 399, etc). Temporary variables used inside the loop body are also private; you can optionally move their declaration inside the loop body because all the variables declared there are automatically private.default(none)– force the programmer to mark all the variables used inside the loop with a data scoping attribute. This is a good practice to avoid bugs.
The loop runtime went down from 1.67 seconds to 0.25 seconds in an environment with eight threads. That’s a speedup of about 6.7. The overall Canny algorithm runtime went down from 3.73 seconds to 2.3 seconds.
Function gaussian_smooth
Function gaussian_smooth was the second function with the longest runtime that was showing up in the performance profile.
We immediately show the OpenMP version, we didn’t change anything related to the source code, we only added OpenMP pragmas to allow parallelization:
#pragma omp parallel shared(rows,cols,center,image,kernel,tempim,smoothedim) private(r,c,cc,rr) default(none)
{
float* dot_arr = calloc(cols, sizeof(float));
float* sum_arr = calloc(cols, sizeof(float));
#pragma omp for
for (r = 0; r < rows; r++) {
memset(dot_arr, 0, cols * sizeof(float));
memset(sum_arr, 0, cols * sizeof(float));
for (cc = (-center); cc <= center; cc++) {
for (c = MAX(0, -cc); c < MIN(cols, cols - cc); c++) {
dot_arr[c] +=
(float)image[r * cols + (c + cc)] * kernel[center + cc];
sum_arr[c] += kernel[center + cc];
}
}
for (c = 0; c < cols; c++) {
tempim[r * cols + c] = dot_arr[c] / sum_arr[c];
}
}
/****************************************************************************
* Blur in the y - direction.
****************************************************************************/
#pragma omp single
if (VERBOSE)
printf(" Bluring the image in the Y-direction.\n");
#pragma omp for
for (r = 0; r < rows; r++) {
memset(dot_arr, 0, cols * sizeof(float));
memset(sum_arr, 0, cols * sizeof(float));
for (rr = (-center); rr <= center; rr++) {
if (((r + rr) >= 0) && ((r + rr) < rows)) {
for (c = 0; c < cols; c++) {
dot_arr[c] +=
tempim[(r + rr) * cols + c] * kernel[center + rr];
sum_arr[c] += kernel[center + rr];
}
}
}
for (c = 0; c < cols; c++) {
(*smoothedim)[r * cols + c] =
(short int)(dot_arr[c] * BOOSTBLURFACTOR / sum_arr[c] + 0.5);
}
}
free(dot_arr);
free(sum_arr);
}
The function gaussian_smooth consists of two loop nests (lines 7-21 and lines 31-47). We used OpenMP pragmas to annotate the source code to allow the distribution to multiple CPU cores.
Pragma #pragma omp parallel at line 1 creates a parallel region. We use shared and private clauses to mark data as private or shared, according to the principles we already explained. Inside the parallel region, each line of code is executed by several threads. So, each thread will allocate a buffer using calloc at lines 8 and 9.
Loops at lines 7 and 31 are compliant with the OpenMP canonical form, so to parallelize them we only added #pragma omp for. Note the line 26, where we added #pragma omp single. We want only one thread to perform the printf, and this pragma makes sure that only one thread executed the command.
So, how did it help reduce the runtime? The function runtime went down from 703 ms to 118 ms on a system with eight threads. The overall Canny algorithm runtime fell from 2.3 seconds to 1.7 seconds.
Function apply_hysteresis
There are several loops inside the function apply_hysteresis, but two of them have a significant performance impact.
The first loop
Here is the source code of the first loop inside apply_hysteresis, we omitted the rest of the code for brevity:
void apply_hysteresis(short int *mag, unsigned char *nms, int rows, int cols,
float tlow, float thigh, unsigned char *edge) {
…
for (r = 0, pos = 0; r<rows; r++){
for (c = 0; c<cols; c++, pos++){
if (edge[pos] == POSSIBLE_EDGE) hist[mag[pos]]++;
}
}
…
}This loop (we call it the histogram computation loop) iterates over the array edge and increases the elements of hist array. Unfortunately, which element of the hist array will get increased will be known only at runtime.
The code hist[mag[pos]] is the spot where we can expect many data cache misses and a huge slowdown; distributing this code to multiple CPUs can bring a large performance increase. This kind of code can be distributed to multiple CPU cores according to the following schema:
- Each thread gets its own private copy of the
histarray. - We distribute the workload to several threads. Each thread gets a part of the iteration space (e.g. thread 0 gets iterations 0-9999, thread 1 gets iteration 10000-19999, etc).
- Threads perform the operation on their own private version of
histarray - At the end, we sum up all the private
histarrays to make the finalhistarray.
In Codee’s terminology, this is called sparse reduction. OpenMP version 4.5 and later supports sparse reduction with a simple syntax. We had to rewrite the loop so it conforms to the OpenMP canonical loop form. Here is the source code:
#pragma omp parallel for private(r,c, pos) shared(edge,mag,rows,cols) reduction(+:hist) default(none)
for (r = 0; r<rows; r++){
pos = r * cols;
for (c = 0; c<cols; c++, pos++){
if (edge[pos] == POSSIBLE_EDGE) hist[mag[pos]]++;
}
}
We got rid of the pos variable from the initialization clause of the loop over r (line 2) to make it conform to the OpenMP canonical form. We marked variables as private or shared, depending on the way they are used.
Note the reduction(+:hist) clause. It specifies that each thread should have a local copy of the hist array. Each thread performs the operations on its own copy; when they all are done, the end array hist is created by summing all the local arrays element-wise.
Subscribe to our newsletter
and receive in-depth technical articles, white papers, videos, webinars, product announcements, and more.
As far as performance is concerned, the Canny algorithm runtime fell down from 1.7 seconds to 1.45 seconds on a system with eight threads. When we measured, originally the loop only took 330 ms and after the distribution to multiple threads it took 57 ms.
The second loop
The source code of the second significant loop in apply_hysteresis function looks like this:
for (r = 0, pos = 0; r<rows; r++){
for (c = 0; c<cols; c++, pos++){
if ((edge[pos] == POSSIBLE_EDGE) && (mag[pos] >= highthreshold)){
edge[pos] = EDGE;
follow_edges((edge + pos), (mag + pos), lowthreshold, cols);
}
}Inside the loop nest there is a call to follow_edges function. In order to tell if we can use OpenMP pragmas to distribute the loop to several CPU cores, the iterations over loop r need to be independent of one another. To find out if this is the case, we need to look inside follow_edges function.
void follow_edges(unsigned char *edgemapptr, short *edgemagptr, short lowval,
int cols)
{
short *tempmagptr;
unsigned char *tempmapptr;
int i;
float thethresh;
int x[8] = { 1, 1, 0, -1, -1, -1, 0, 1 },
y[8] = { 0, 1, 1, 1, 0, -1, -1, -1 };
for (i = 0; i<8; i++){
tempmapptr = edgemapptr - y[i] * cols + x[i];
tempmagptr = edgemagptr - y[i] * cols + x[i];
if ((*tempmapptr == POSSIBLE_EDGE) && (*tempmagptr > lowval)){
*tempmapptr = (unsigned char)EDGE;
follow_edges(tempmapptr, tempmagptr, lowval, cols);
}
}
}
This code takes a pixel, then it iterates through eight surrounding pixels. If their value is POSSIBLE_EDGE, it will change its value to EDGE and then recursively call the same function on the new pixel.
The iterations are not independent. Depending on the way the iterations are distributed we might get a different result. This kind of code cannot be efficiently parallelized without altering the structure of this algorithm. So this code remains as it is, unparallelized.
Function magnitude_x_y
Here is the source code of function magnitude_x_y:
void magnitude_x_y(short int *delta_x, short int *delta_y, int rows, int cols,
short int **magnitude)
{
int r, c, pos, sq1, sq2;
/****************************************************************************
* Allocate an image to store the magnitude of the gradient.
****************************************************************************/
if ((*magnitude = (short *)calloc(rows*cols, sizeof(short))) == NULL){
fprintf(stderr, "Error allocating the magnitude image.\n");
exit(1);
}
for (r = 0, pos = 0; r<rows; r++){
for (c = 0; c<cols; c++, pos++){
sq1 = (int)delta_x[pos] * (int)delta_x[pos];
sq2 = (int)delta_y[pos] * (int)delta_y[pos];
(*magnitude)[pos] = (short)(0.5 + sqrt((float)sq1 + (float)sq2));
}
}
}The loop nest at lines 14-20 is computation heavy, but the iterations are independent of one another and can be easily distributed to several CPU cores. To do this, we need to convert the loop over r (line 14) to OpenMP canonical form by getting rid of the induction variable pos. The result looks like this:
#pragma omp parallel for private(r,c,pos,sq1,sq2) shared(rows,cols,delta_x,delta_y,magnitude) default(none)
for (r = 0; r<rows; r++){
pos = r * cols;
for (c = 0; c<cols; c++, pos++){
sq1 = (int)delta_x[pos] * (int)delta_x[pos];
sq2 = (int)delta_y[pos] * (int)delta_y[pos];
(*magnitude)[pos] = (short)(0.5 + sqrt((float)sq1 + (float)sq2));
}
}
The runtime of the loop went down from 264 ms to 40 ms. The Canny algorithm runtime went from 1.45 seconds to 1.2 seconds.
Function derivative_x_y
Source code of function derivative_x_y looks like this (irrelevant parts omitted for brevity):
void derrivative_x_y(short int *smoothedim, int rows, int cols,
short int **delta_x, short int **delta_y)
{
int r, c, pos;
...
/****************************************************************************
* Compute the x-derivative. Adjust the derivative at the borders to avoid
* losing pixels.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Computing the X-direction derivative.\n");
for (r = 0; r<rows; r++){
pos = r * cols;
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos];
pos++;
for (c = 1; c<(cols - 1); c++, pos++){
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos - 1];
}
(*delta_x)[pos] = smoothedim[pos] - smoothedim[pos - 1];
}
/****************************************************************************
* Compute the y-derivative. Adjust the derivative at the borders to avoid
* losing pixels.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Computing the Y-direction derivative.\n");
for (c = 0; c < cols; c++) {
pos = c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos];
pos = rows * (rows - 1) + c;
(*delta_y)[pos] = smoothedim[pos] - smoothedim[pos - cols];
}
for (r = 1; r < (rows - 1); r++) {
for (c = 0; c < cols; c++) {
pos = r * cols + c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos - cols];
}
}
}
The three loops presented above can be easily parallelized, because, for each loop, each iteration writes to a different element of the output arrays delta_x or delta_y. We can distribute them in one go using OpenMP directives. Here are the same loops, but decorated with OpenMP pragmas.
#pragma omp parallel shared(rows,cols,delta_x,delta_y,smoothedim) private(r,c,pos) default(none)
{
#pragma omp for
for (r = 0; r<rows; r++){
pos = r * cols;
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos];
pos++;
for (c = 1; c<(cols - 1); c++, pos++){
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos - 1];
}
(*delta_x)[pos] = smoothedim[pos] - smoothedim[pos - 1];
}
/****************************************************************************
* Compute the y-derivative. Adjust the derivative at the borders to avoid
* losing pixels.
****************************************************************************/
#pragma omp single
if (CANNY_LIB_VERBOSE) printf(" Computing the Y-direction derivative.\n");
#pragma omp for
for (c = 0; c < cols; c++) {
pos = c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos];
pos = rows * (rows - 1) + c;
(*delta_y)[pos] = smoothedim[pos] - smoothedim[pos - cols];
}
#pragma omp for
for (r = 1; r < (rows - 1); r++) {
for (c = 0; c < cols; c++) {
pos = r * cols + c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos - cols];
}
}
}
We’ve already seen a similar OpenMP pragma pattern in function gaussian_smooth, so we won’t go over it again.
The function runtime went down from 156 ms to 52 ms and the Canny algorithm runtime went down from 1.2 seconds to 1.1 seconds.
The end profile
The end profile looks like this:

We’ve managed to speed up most of the functions. The ones that now dominate the profile are unparallelizable: apply_hysteresis and write_pgm_image. Function apply_hysteresis is partially unparallelizable, the other functions are IO bound, and speeding up those is not possible with parallelization.
Conclusion
At the beginning of the post, the Canny algorithm took 3.7 seconds to complete. After the work was done, the time was reduced to 1.1 seconds. The speedup factor was about 3.4 on a system with eight threads. Notice that our program was not running on eight threads for the whole time.
If we add up all the loop runtimes before the parallelization we get the number of 3.128 seconds. After the parallelization the same loops took 0.517 seconds. The speedup factor for the code we parallelized is around 6, which is a much better number. The non parallelizable part of code takes 0.61 seconds. That means that unparallelizable functions now dominate the performance profile. This is a clear demonstration of Amdahl’s law: after speeding up the parallelizable part as much as possible, the non-parallelizable part is the limiting factor in our system. Even if we had an endless amount of CPUs and zero parallelization overhead, our program would not run faster than 0.61 seconds.
When we started with the Canny in the previous post, the whole program (the Canny algorithm and reading/writing images) took 12.9 seconds. The optimized serial version of Canny which we used as a starting point in this post took 4 seconds, and the multithreaded version took 1.5 seconds. That’s an overall speedup of more than eight times!
About OpenMP: OpenMP is a light approach to distribute the workloads to several CPU cores, supported by all major compilers. It is especially useful for legacy codebases since the overhead is very low, but it is also useful for newly developed codes. It shares drawbacks with all other multithreading frameworks: there is a new class of bugs related to race conditions, access to unprotected variables, overhead on small input sizes.
In the upcoming posts we will investigate Codee for this same problem: we will check its autoparallelization capabilities, and also we will present a few ways it can help you catch bugs in the development process. We also plan to compare different types of loops based on their arithmetic intensity, memory access pattern, etc. and see how the speedup using multithreading depends on those parameters.
Additional information
You can easily see the changes we made by comparing the source file canny-original.c and canny-optimized.c.
All the tests were executed on AMD Ryzen 7 4800H CPU with 16 cores and 16 GB of RAM memory with GCC 9.3 compiler on Ubuntu 20.04. We disabled processor frequency scaling in order to decrease runtime variance. The reported runtimes are averaged for 36 runs.
🔗 Read part 1 of ‘How we made the Canny edge detector run faster‘
1 The version of the Canny algorithm we used as a starting point here differs slightly from the version obtained as a result of optimization in the previous post. More on this later.
2 In the SIMD world, there is no such thing as conditional execution. Conditional execution is simulated by executing both the commands in the true branch and in the false branch, and then using bitmasking to choose the correct value depending on the condition.
3 Independent iterations mean that the input values used in the current iteration do not depend on the output values produced in the previous iterations. This allows us to iterate the loop in any way we like and the output result will be the same. In the case of multithreading we can split the iteration space 0..N into subranges, 0 .. N1, .., Nm … N and assign each subrange to a dedicated thread.
Build correct, secure, modern and fast Fortran, C and C++ scientific software
Leave a Reply