Canny edge detector algorithm is a famous algorithm in image processing. One of our customers was inquiring about the performance of that algorithm, so our performance engineers took a look.
As always when dealing with unfamiliar codebases, we didn’t know what to expect. Some algorithms have a lot of room for performance improvements, others don’t. The implementation we got was a C implementation with a lot of obsolete constructs (loops running over pointers, functions without return types, etc.) that you don’t see a lot nowadays.
In this post we will talk about the modifications we did to the serial version of Canny. With these changes the hardware can execute the code faster and the compiler can optimize it better. We didn’t use multiple CPU cores or offloading to the graphic card to speed it up, we leave that for our next post.
Profiling
The first step was to use a profiler to figure out which functions take a lot of time. Here is the flamegraph of the Canny algorithm for a really large image (15360 x 8640 pixels).
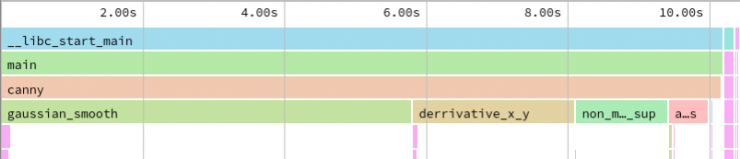
Four functions clearly dominate the profile: gaussian_smooth, derivative_x_y, non_max_supp and apply_hysteresis. We didn’t know what the functions do, but we did know what are the key principles that the code must obey in order to be fast. So let’s dig into the code:
Analysis
Function gaussian_smooth
Here is the source code of the gaussian_smooth function (only relevant parts):
void gaussian_smooth(unsigned char *image, int rows, int cols, float sigma,
short int **smoothedim)
{
int r, c, rr, cc, /* Counter variables. */
windowsize, /* Dimension of the gaussian kernel. */
center; /* Half of the windowsize. */
float *tempim, /* Buffer for separable filter gaussian smoothing. */
*kernel, /* A one dimensional gaussian kernel. */
dot, /* Dot product summing variable. */
sum; /* Sum of the kernel weights variable. */
...
/****************************************************************************
* Blur in the x - direction.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Bluring the image in the X-direction.\n");
for (r = 0; r<rows; r++){
for (c = 0; c<cols; c++){
dot = 0.0;
sum = 0.0;
for (cc = (-center); cc <= center; cc++){
if (((c + cc) >= 0) && ((c + cc) < cols)){
dot += (float)image[r*cols + (c + cc)] * kernel[center + cc];
sum += kernel[center + cc];
}
}
tempim[r*cols + c] = dot / sum;
}
}
/****************************************************************************
* Blur in the y - direction.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Bluring the image in the Y-direction.\n");
for (c = 0; c<cols; c++){
for (r = 0; r<rows; r++){
sum = 0.0;
dot = 0.0;
for (rr = (-center); rr <= center; rr++){
if (((r + rr) >= 0) && ((r + rr) < rows)){
dot += tempim[(r + rr)*cols + c] * kernel[center + rr];
sum += kernel[center + rr];
}
}
(*smoothedim)[r*cols + c] = (short int)(dot*BOOSTBLURFACTOR / sum + 0.5);
}
}
free(tempim);
free(kernel);
}Two loop nests are clearly visible: a loop nest that does the blurring in the x-direction (lines 18-30), and a loop nest that blurs in the y-direction (lines 36-48).
These are the rules of thumb to get good performance in this type of code:
- When iterating over arrays or matrices, all the memory accesses should be sequential 1. We want to avoid strided 2 and random accesses 3 as much as possible.
- The innermost loop should have a lot of iterations (high trip count). This will make more optimizations opportunities available to the compiler through vectorization, loop unrolling, loop interleaving or software pipelining, etc.
- Move all loop-invariant computations outside of the loop. The smaller the loop body, the faster it will run.
Applying these principles will allow the hardware to do its job as fast as possible, also it will allow the compiler to generate the most efficient version of the code by vectorizing the innermost loop. When we say vectorization, we mean that the compiler will generate special SIMD instructions that are faster than the regular instructions because they process more than one piece of data with a single instruction.
Let’s see how our code relates to these principles. In the first loop nest (lines 18-30), doing blurring in the x-direction, all memory accesses are sequential. Inside the innermost loop there is a condition if (((c + cc) >= 0) && ((c + cc) < cols)) (line 23) that checks for memory out of bound access. This code is loop invariant; we can move it outside of the loop by changing the loop start and end conditions.
It is not clear what the trip count of the innermost loop (line 22) is by just looking at the code. When we measured on a real input image, the loop count was really low, only 5. This is too small of a number for the compiler to work on, but luckily, the outer loop that iterates over variable c has a high trip count. We can interchange the two loops (line 22 and line 19); by doing this we wouldn’t be introducing any non-sequential memory accesses. To make the interchange possible, however, we need to introduce a temporary array to store the intermediate results.
So, here is how our loop nest looks when transformed:
float* dot_arr = calloc(cols, sizeof(float));
float* sum_arr = calloc(cols, sizeof(float));
for (r = 0; r < rows; r++) {
memset(dot_arr, 0, cols * sizeof(float));
memset(sum_arr, 0, cols * sizeof(float));
for (cc = (-center); cc <= center; cc++) {
for (c = MAX(0, -cc); c < MIN(cols, cols - cc); c++) {
dot_arr[[c]] +=
(float)image[r * cols + (c + cc)] * kernel[center + cc];
sum_arr[[c]] += kernel[center + cc];
}
}
for (c = 0; c < cols; c++) {
tempim[r * cols + c] = dot_arr[[c]] / sum_arr[[c]];
}
}We introduced two new temporary arrays dot_arr and sum_arr (lines 1 and 2) to hold the temporary values. Please also note that we moved the innermost if condition outside of the loop, by changing the loop boundaries (line 8). This loop nest is now hardware and compiler friendly.
The second loop nest looks like this:
for (c = 0; c<cols; c++){
for (r = 0; r<rows; r++){
sum = 0.0;
dot = 0.0;
for (rr = (-center); rr <= center; rr++){
if (((r + rr) >= 0) && ((r + rr) < rows)){
dot += tempim[(r + rr)*cols + c] * kernel[center + rr];
sum += kernel[center + rr];
}
}
(*smoothedim)[r*cols + c] = (short int)(dot*BOOSTBLURFACTOR / sum + 0.5);
}
}It looks similar to the previous loop nest, but it is much more inefficient. Access to the arrays tempim (line 7) and smoothedim (line 11) is with stride cols which is really bad for performance. The innermost loop (line 5) has a low trip count (same as the previous loop nest). And there is a condition inside the innermost loop that we can move outside of the loop (line 6).
We can safely interchange loop over variable c (line 1) and loop over variable r (line 2) and get rid of non-sequential accesses. But ideally, we want to move the short innermost loop over rr (line 5) and interchange it with other loops that have a higher trip count. Actually, with an introduction of temporary arrays to hold intermediate values we can do this, and our code looks like this:
for (r = 0; r<rows; r++){
memset(dot_arr, 0, cols * sizeof(float));
memset(sum_arr, 0, cols * sizeof(float));
for (rr = (-center); rr <= center; rr++){
if (((r + rr) >= 0) && ((r + rr) < rows)){
for (c = 0; c<cols; c++){
dot_arr[[c]] += tempim[(r + rr) * cols + c] * kernel[center + rr];
sum_arr[[c]] += kernel[center + rr];
}
}
}
for (c = 0; c < cols; c++) {
(*smoothedim)[r*cols + c] = (short int)(dot_arr[[c]]*BOOSTBLURFACTOR / sum_arr[[c]] + 0.5);
}
}
This transformation is more complex. We completely rearranged the loops, from (c, r, rr) to (r, rr, c), and by doing this we’ve made our code much hardware friendlier and easier for the compiler to optimize.
For both loop nests, in the original version, CLANG compiler didn’t vectorize the innermost loop. Its cost model calculated that the loop was not worth vectorizing, both because of the low trip count and non-sequential memory access pattern. For the optimized version, CLANG vectorized innermost loop for both loop nests.
The runtime of the function gaussian_smooth fell down from 5.4 seconds to 0.5 seconds. The overall program runtime went down from 9 seconds to 4.5 seconds. The function basically became irrelevant as far as overall time consumption.
Function derivative_x_y
The second function that dominates the performance profile is derivative_x_y. Let’s look at the source code (only relevant parts):
void derrivative_x_y(short int *smoothedim, int rows, int cols,
short int **delta_x, short int **delta_y)
{
int r, c, pos;
...
/****************************************************************************
* Compute the x-derivative. Adjust the derivative at the borders to avoid
* losing pixels.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Computing the X-direction derivative.\n");
for (r = 0; r<rows; r++){
pos = r * cols;
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos];
pos++;
for (c = 1; c<(cols - 1); c++, pos++){
(*delta_x)[pos] = smoothedim[pos + 1] - smoothedim[pos - 1];
}
(*delta_x)[pos] = smoothedim[pos] - smoothedim[pos - 1];
}
/****************************************************************************
* Compute the y-derivative. Adjust the derivative at the borders to avoid
* losing pixels.
****************************************************************************/
if (CANNY_LIB_VERBOSE) printf(" Computing the Y-direction derivative.\n");
for (c = 0; c<cols; c++){
pos = c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos];
pos += cols;
for (r = 1; r<(rows - 1); r++, pos += cols){
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos - cols];
}
(*delta_y)[pos] = smoothedim[pos] - smoothedim[pos - cols];
}
}This function again consists of two loop nests. The first loop nest (lines 13-21) computes the derivative in the X direction, the second loop (lines 28-36) computes it in the Y direction.
The first loop nest looks good. The innermost loop has a high trip count and all the memory accesses are to sequential memory addresses.
The second loop nest however looks bad. Memory accesses to the arrays are with stride cols, which is bad for performance. To perform the loop interchange, the loop over c (line 28) and loop over r (line 32) should be perfectly nested, which is not the case here (lines 29-31 and line 35 are preventing the interchange).
We can perform the interchange, however, by splitting the loop over variable c (lines 28-36) into two loops. The first loop would deal with the code that is preventing us from doing the interchange. The second loop would be perfectly nested with the inner loop, thus allowing loop interchange. Here is how the transformation looks like for the second loop:
for (c = 0; c < cols; c++) {
pos = c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos];
pos = rows * (rows - 1) + c;
(*delta_y)[pos] = smoothedim[pos] - smoothedim[pos - cols];
}
for (r = 1; r < (rows - 1); r++) {
for (c = 0; c < cols; c++) {
pos = r * cols + c;
(*delta_y)[pos] = smoothedim[pos + cols] - smoothedim[pos - cols];
}
}We split the original loop nest into two loop nests (lines 1-6 and lines 8-13). The first loop (line 1) deals with the edge cases that were preventing loop interchange. The second loop nest (line 7) now processes data sequentially. The first loop is not optimal, but it has only cols iterations, compared to the second loop which has cols * (rows - 1) iterations and which dominates the runtime.
In the original function, CLANG vectorized the innermost loop in the first loop nest, but not in the second. Its cost model again predicted that the vectorization is inefficient due to non-sequential memory access pattern. In the optimized version, CLANG vectorized innermost loop in both loop nests.
The runtime of the function derrivative_x_y went down from 2.8 seconds to 0.15 seconds. The overall program runtime went down from 4.5 seconds to 1.8 seconds.
Function non_max_supp
This is a really long function that is showing up in the performance profile, so we are omitting its source code here.
Its main loop body processes pixels row-wise which is good for the performance. For each pixel, it also accesses the neighboring pixels, but which pixels are accessed depends on a complicated set of nested if conditions.

Subscribe to our newsletter
and receive in-depth technical articles, white papers, videos, webinars, product announcements, and more.
The major slowdown in this case comes from the nested if conditions. This type of code causes a large number of branch mispredictions, and each misprediction is costly. One way to speed it up is to go branchless.
Going branchless didn’t bring the expected speedup because there was a lot of work to be done in the branch bodies. So, no significant speedup was possible by rewriting parts of this function.
Function apply_hysteresis
Function apply_hysteresis is a longer function consisting of several loops. Some loops iterate over sequential memory locations, and these are fine; others iterate over strided memory locations, but there is nothing we can do about it since these are simple loops where no interchange is possible. E.g. one such loop:
for (r = 0, pos = 0; r<rows; r++, pos += cols){
edge[pos] = NOEDGE;
edge[pos + cols - 1] = NOEDGE;
}However, one loop stands out: the histogram computing loop. It looks like this:
int hist[32768];
for (r = 0, pos = 0; r<rows; r++){
for (c = 0; c<cols; c++, pos++){
if (edge[pos] == POSSIBLE_EDGE) hist[mag[pos]]++;
}
}
This loop computes a histogram over a really large iteration space. Access to array hist (line 5) is random, which is bad, and the worse thing is that no vectorization is possible due to possible dependencies. Imagine that mag[0] = 10 and mag[1] = 10. If this is the case, executing hist[mag[0]]++ and hist[mag[1]]++ in parallel would give an undefined result.
It is however possible to speed up histograms with a trick. Instead of having one histogram array, let’s have two. In that case we could unroll a loop by a factor of two and perform two histograms in parallel (modern architectures can perform several instructions at once if the instructions do not depend on one another).
int hist[32768], hist1[32768];
memset(hist, 0, 32768 * sizeof(int));
memset(hist1, 0, 32768 * sizeof(int));
int end = (rows * cols) / 2 * 2;
for (pos = 0; pos < end; pos+=2) {
hist[mag[pos]] += (edge[pos] == POSSIBLE_EDGE);
hist1[mag[pos + 1]] += (edge[pos + 1] == POSSIBLE_EDGE);
}
if (end != rows * cols) {
hist[mag[end]] += (edge[end] == POSSIBLE_EDGE);
}
for (pos = 0; pos < 32768; pos++) {
hist[pos] += hist1[pos];
}
The speed up was more modest this time. Originally the function took 640 ms to execute, with the change this time went down to 450 ms. Overall program runtime went down from 1.8 seconds to 1.6 seconds.
Conclusion
There was a lot of speed up potential in this implementation of Canny edge detector. By making modest changes to the Canny source code, the runtime went down from 9 seconds to 1.6 seconds which is a remarkable result. The key to having good performance is focusing on the hot loops, and making sure there is a good memory access pattern and enough iterations for the compiler to be able to do its job.
If we wanted even more speed, we would have to move from a serial to parallelized version of the code. We will cover parallelization in our next post.
Additional information
You can easily see the changes we made by comparing the source file canny-original.c and canny-optimized.c.
All the tests were executed on AMD Ryzen 7 4800H CPU with 16 cores and 16 GB of RAM memory with CLANG 10 compiler on Ubuntu 20.04.
🔗 Go to part 2 of ‘How we made the Canny edge detector run faster‘
1 Sequential access means that the program is accessing neighboring memory addresses: a[0], a[1], a[2], etc.
2 Strided access means that the program is accessing memory addresses which are not neighboring, but with a constant stride, e.g: a[0], a[4], a[8], etc.
3 Random access means that the program is accessing memory addresses in random order, e.g. a[5], a[28], a[11], a[141], etc.
Build correct, secure, modern and fast Fortran, C and C++ scientific software
Leave a Reply